Lately I’ve been working with a lot of teams and founders that are building products on top of LLMs. It’s a lot of fun!
To be an AI product engineer today is to constantly ask new questions that impact how you build products. Questions like:
- “Is there a way we can reliably prevent prompt injection?” Likely no
- “Will GPT-4o mini outperform Llama 3.1 70B on this prompt?” Probably not
- “Can we train a faster model to replace our use of OpenAI for this classification task?” Perhaps yes
- “Should stay within a 64k context budget, even though the model supports 128k now?” Likely yes
Interesting questions, and answerable with some mix of experimentation and discussion with other AI teams.
However, a common question comes up that is not easy to answer: “Will this problem still matter when GPT-5 comes out?” This is a fun one: it’s a bit silly and speculative, but also potentially an existential risk to any given business.
Of course, we don’t know exactly what the next generation of frontier models will bring. But we can make some pretty safe bets. They’ll:
- Seem meaningfully smarter
- Follow more complex instructions more faithfully
- Reduce the engineering lift needed to apply AI to certain problems
- Expand the set of problems AI can be applied to at all.
While product teams need to focus on building things that are useful today, we do benefit from considering where the puck is going. Otherwise, we might build a business around something that, in a year or two, stops being useful. If your product was “A JSON formatter for LLM output,” you’re probably done now.
Sam Altman has intentionally fanned the flames here, explicitly warning startups that if you build minor improvements on top of GPT-4, assuming that the models won’t get much better, “We’re gonna steamroll you.” Even accounting for his self-interested tendency to hype future models, it’s hard to deny the risk: nobody wants to start, invest in, or go work for a company that will shortly be obsoleted.
So how do you know if a given LLM-powered product company will end up obsoleted by model improvements? OpenAI’s Greg Brockman proposed a test:
Ask the company if a 100x improvement in the model would be something they’re excited about. We can tell pretty well, because we know the companies that come to us saying, “We want the next model, when is it coming out, I want to be the first to try it, it’s going to be the best thing for my company.” … If there’s a clear path to how better underlying intelligence accelerates that product, then that’s a pretty good delineation.
The basic idea here is to make products that will be more useful when the models get way better. Do that, and the rising tide should lift you as you go.
Given this, Y Combinator startups building on AI (which is most of them, reportedly) are often advised that even if current AI models aren’t quite powerful enough for their product to work well, that’s okay. When the next big model comes along, the theory goes, teams that were previously pushing the limits of the frontier models will be prepared to make the best use of the new stuff.
Put another way: in tech, building for the near future is reasonable.
However. If you’re spending all day working on a product that doesn’t quite work yet due to limitations with GPT-4o and other frontier models, you’re going to be really curious: Is it worth trying to eke out 5% better performance for this sub-prompt, or should we just refine our UX while we wait for the models to get better? When is that next frontier leap coming?
It’s a fun thing to speculate about. Luckily, there’s enough info out there to make a defensible projection.
In a June Stratechery interview, Nat Friedman (not an OpenAI employee, but someone in a position to know) gave a timeline for the next big leap:
It takes about three years to roll new models, new big pre-trainings. So we’re kind of in the post-4, pre-5 era. During this time, innovation has shifted to post-training, and we’ve actually learned that you can do a lot in post-training – it can improve a lot.
Three years? Woof. The GPT-4-class era started in March ’23, so that would put the GPT-5 era in early 2026.
While Sam Altman has been obliquely hinting that GPT-5 might come in 2024 for a while, an end-of-2025 timeline meshes with another interview, also in June, where OpenAI CTO Mira Murati said to expect GPT’s performance to jump from “smart high-schooler” to “Ph.D level intelligence” in about 1.5 years, or roughly December 2025.
So on OpenAI’s roadmap, it seems the next huge leap is on track for roughly the end of of 2025. That’s a long time, at least for teams that are betting on this leap for their products to fully work.
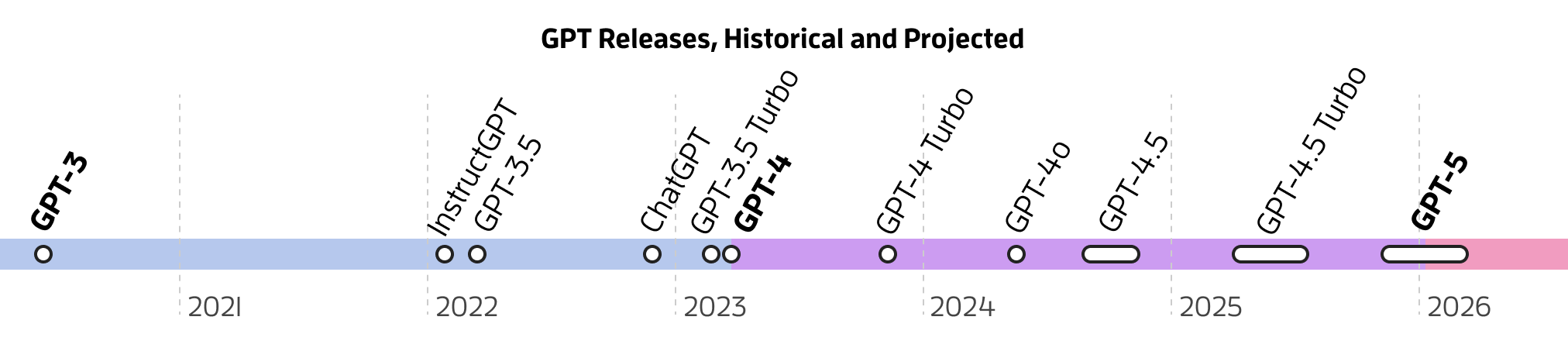
Luckily, meaningful incremental improvements are inbound in the meantime. At the GPT-4o event back in May, Murati promised that the “next big thing” was coming “soon.” While this could be GPT-5, it pairs better with rumours of a GPT-4.5-like model coming this fall. Some users have also recently seen glitches where ChatGPT briefly shows “GPT-4.5” in the model selector.
Even if OpenAI might not achieve what we might think of as GPT-5-class performance for some time yet, it’s worth noting that they might not even be the first to get there. Back in 2022, GPT-4 was the only model being trained with compute of that scale. Today, a herd of big players have invested billions into AI hardware. Claude 3.5 Sonnet and Llama 3.1 405B are just two of the many OpenAI-caliber frontier models we have today – and a larger Claude 3.5 Opus is coming “later this year”.
One way or another, the now long-held status quo, with GPT-4 defining the frontier of LLMs, seems poised to end. Some products are going to get steamrolled, and others that just barely work today are going to suddenly thrive. It continues to be a wild world.
Still, try not to lose sleep over it. There is so much to do still, even with what we already have. To do that, we need to stay focused on the core thing that matters: building useful stuff.